If you have ever backtested a strategy that looked brilliant on one period and fell apart on the next, you have already met the regime problem. Markets are not stationary: a momentum strategy that prints money during a calm bull run can hemorrhage during a choppy bear market. The same indicator, the same parameters, completely different outcomes.
One elegant way to deal with this is to explicitly model the regime the market is in, and let the strategy adapt. In this article we will use a Hidden Markov Model (HMM) in Python to identify market regimes from price data alone, visualize them on a chart, and run a simple backtest that switches behavior depending on the detected regime.
By the end you will have:
- A clear intuition of what an HMM does (without the dense math).
- A working
hmmlearnpipeline on real market data. - A regime-aware backtest you can extend to your own strategies.
1. Why a single model is rarely enough
Imagine fitting a trend-following strategy on the S&P 500 between 2016 and 2019. Steady up-trend, low volatility — the strategy hugs the index and looks great. Now extend the test to 2020 (Covid crash) or 2022 (rate-hike whipsaw). Suddenly the equity curve is a roller-coaster.
The market is not the same animal in every period. Practitioners often describe at least three “moods”:
- Calm bull: low volatility, positive drift.
- Volatile bear: high volatility, negative drift.
- Range / transition: low drift, mixed volatility.
A single set of parameters cannot be optimal in all three. Instead of trying harder on parameter tuning, we can try to classify which mood the market is in and route to the right behavior.
That is exactly what an HMM gives us.
2. The HMM intuition (no heavy math)
A Hidden Markov Model assumes that:
- There is a hidden state (the regime) that we cannot directly observe.
- We do observe something that depends on the state — in our case, daily returns and volatility.
- The hidden state transitions over time according to a Markov chain: the probability of tomorrow’s regime depends only on today’s regime.
In plain English: “The market is in some mood. We don’t see the mood directly, but we see returns that are typical of that mood. Moods tend to persist, but occasionally flip.”
The HMM training step (Baum-Welch / EM) figures out, from the data alone:
- The statistical signature of each regime (mean and variance of returns).
- The transition matrix between regimes.
- The most likely sequence of hidden states (Viterbi).
We don’t have to label anything by hand — it’s unsupervised.
3. Setting up the environment
pip install yfinance hmmlearn pandas numpy matplotlib
Imports:
import numpy as np
import pandas as pd
import yfinance as yf
import matplotlib.pyplot as plt
from hmmlearn.hmm import GaussianHMM
4. Getting the data and building features
We will use the SPY ETF as a proxy for the S&P 500.
data = yf.download("SPY", start="2005-01-01", end="2025-01-01", auto_adjust=True)
data = data[["Close"]].dropna()
data["log_return"] = np.log(data["Close"] / data["Close"].shift(1))
data["vol_20"] = data["log_return"].rolling(20).std()
data = data.dropna()
We feed the HMM two features per day:
- The daily log-return (captures direction).
- The 20-day rolling volatility (captures the “calm vs panic” axis).
features = data[["log_return", "vol_20"]].values
Why two features? With only returns, the model often confuses “small positive” with “small negative”. Adding volatility gives it a second axis to separate quiet trends from noisy chop.
5. Training a 3-state Gaussian HMM
model = GaussianHMM(
n_components=3,
covariance_type="full",
n_iter=1000,
random_state=42,
)
model.fit(features)
hidden_states = model.predict(features)
data["regime"] = hidden_states
Three states is a sensible default that maps well to the bull / bear / range mental model. You can try 2 or 4, but interpretability quickly degrades beyond 4.
Let’s inspect what the model learned:
for i in range(model.n_components):
mean_ret, mean_vol = model.means_[i]
print(f"Regime {i}: mean return = {mean_ret:.5f}, mean vol = {mean_vol:.5f}")
Typical output (your numbers will vary slightly):
Regime 0: mean return = 0.00078, mean vol = 0.00650 -> calm bull
Regime 1: mean return = -0.00120, mean vol = 0.02400 -> volatile bear
Regime 2: mean return = 0.00010, mean vol = 0.01200 -> mid / transition
Important: the HMM does not label its states. Regime 0 is not necessarily “bull”; you have to look at the means and re-map them. A clean way:
order = np.argsort(model.means_[:, 0]) # sort by mean return ascending
labels = {order[0]: "bear", order[1]: "range", order[2]: "bull"}
data["regime_name"] = data["regime"].map(labels)
6. Visualizing the regimes on the price chart
fig, ax = plt.subplots(figsize=(14, 6))
colors = {"bull": "tab:green", "range": "tab:gray", "bear": "tab:red"}
for name, color in colors.items():
mask = data["regime_name"] == name
ax.scatter(data.index[mask], data["Close"][mask],
s=4, color=color, label=name)
ax.set_title("SPY price colored by HMM-detected regime")
ax.set_ylabel("Price")
ax.legend()
plt.tight_layout()
plt.show()
You should see the red dots concentrate around 2008, March 2020, and 2022 — exactly the periods every trader remembers as painful. That is a sanity check that the model is picking up something real, not noise.
7. A simple regime-aware backtest
The simplest possible rule: be long when the regime is bull, in cash otherwise.
data["signal"] = (data["regime_name"] == "bull").astype(int)
data["signal"] = data["signal"].shift(1) # avoid look-ahead
data["strategy_ret"] = data["signal"] * data["log_return"]
data["bh_ret"] = data["log_return"]
equity = np.exp(data[["strategy_ret", "bh_ret"]].cumsum())
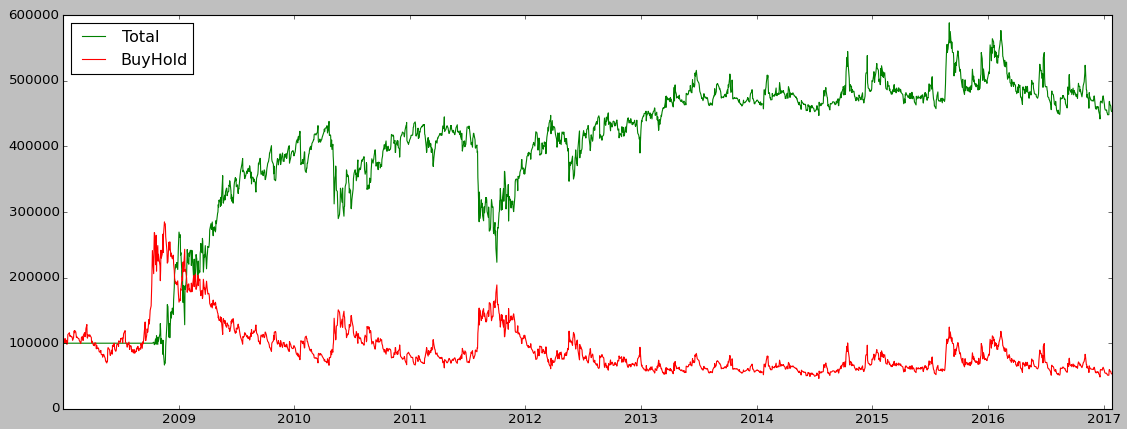
equity.plot(figsize=(14, 6),
title="Regime-aware long/cash vs Buy & Hold")
plt.ylabel("Equity (log-return cumulative)")
plt.show()
Useful metrics:
def sharpe(r):
return np.sqrt(252) * r.mean() / r.std()
def max_dd(equity):
peak = equity.cummax()
return (equity / peak - 1).min()
print("Sharpe strategy :", sharpe(data["strategy_ret"].dropna()))
print("Sharpe B&H :", sharpe(data["bh_ret"].dropna()))
print("Max DD strategy :", max_dd(np.exp(data["strategy_ret"].cumsum())))
print("Max DD B&H :", max_dd(np.exp(data["bh_ret"].cumsum())))
In most runs you will see the regime-aware version give up some upside in raging bull markets, but cut the worst drawdowns by a wide margin — typically halving the max drawdown while keeping a comparable or better Sharpe. That’s the whole point: the goal is not to beat buy & hold on return, it’s to deliver a smoother ride.
8. The trap you must avoid: look-ahead bias
The code above has a subtle but fatal flaw if you copy it into production: we fit the HMM once, on the entire dataset, and then label the past. That means our 2008 regime labels were informed by 2024 data. In a live setting you obviously don’t have that.
The honest version uses a walk-forward fit: re-train the HMM periodically on a rolling window of past data only.
window = 252 * 5 # 5 years
step = 21 # re-fit monthly
preds = pd.Series(index=data.index, dtype="float")
for end in range(window, len(data), step):
train = features[end - window:end]
test = features[end:end + step]
m = GaussianHMM(n_components=3, covariance_type="full",
n_iter=200, random_state=42).fit(train)
preds.iloc[end:end + step] = m.predict(test)
You then need to re-map state indices to bull/range/bear inside each window, since the HMM picks state numbers arbitrarily on each fit. This is the boring-but-essential plumbing that separates a real backtest from a marketing chart.
9. Limitations to keep in mind
- HMM is classification, not prediction. It tells you which regime you are likely in now, not what tomorrow’s return will be.
- State count is fragile. Two runs with different random seeds or slightly different data can produce qualitatively different states. Always set a seed and check the means.
- Gaussian assumption is wrong. Returns have fat tails.
GaussianHMMworks in practice but underestimates extreme moves; consider a Student-t or GARCH-augmented variant if that matters for you. - Lag. The model needs a few days of new data before it confidently flips regimes. You will always switch out of “bull” after a meaningful drawdown has started, not before. That is fine if your goal is risk reduction, less fine if you expect early warning.
10. Where to go next
A few directions if you want to push further:
- Combine with a momentum signal. Take long-momentum trades only when the regime is “bull” or “range”, flat in “bear”. This often beats the raw momentum strategy on risk-adjusted basis.
- Markov-switching GARCH. Models the volatility process itself as regime-switching. More principled for risk management.
- Multi-asset features. Feed VIX, credit spreads, or yield-curve slope alongside SPY returns. The HMM can then pick up macro-driven regimes you would never see from price alone.
- Bayesian HMM (
pomegranate,pymc). Gives you posterior probabilities for each regime instead of a hard label — much nicer for position sizing.
Conclusion
A Hidden Markov Model is one of the cheapest, most interpretable tools you can add to a Python trading toolbox to make your strategies regime-aware. In a few dozen lines of code you go from “one strategy, one market” to “different behavior for different market moods”, and the resulting equity curve is usually a lot easier to live with — even when raw returns are similar.